
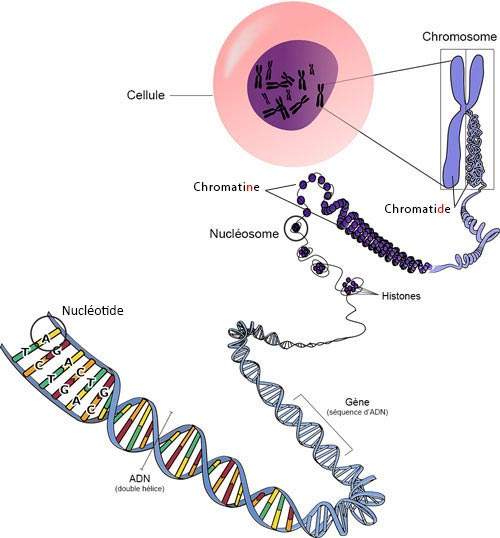
ADN est l’abréviation d’Acide Désoxyribonucléique
L’ADN est une molécule d’importance biologique fondamentale, car elle constitue le support de l’information génétique : elle est le principal véhicule du phénomène de l’hérédité. Du point de vue chimique, l’ADN est un acide faible, constitué d’une série d'éléments appelés nucléotides.
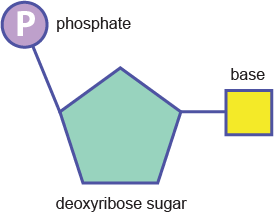
Chaque nucléotide est à son tour un ensemble de trois parties :
un groupe phosphate (constitué d’un atome de phosphore relié à quatre atomes d’oxygène),
le désoxyribose (un sucre à cinq atomes de carbone semblable au ribose, mais avec un groupe hydroxyle en moins), qui donne son nom à la molécule,
et une base azotée (une molécule complexe faite d’un ou de deux cycles contenant des atomes d’azote et de carbone).
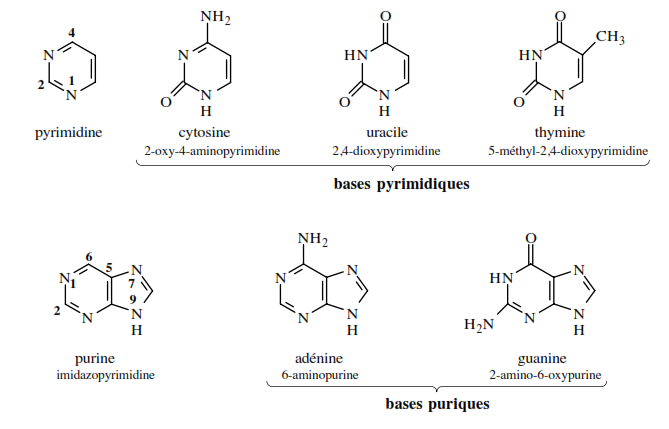
Alors que tous les groupes phosphate et toutes les molécules de désoxyribose qui composent l’ADN sont identiques, les bases peuvent être de quatre types, distribuées de façon différente le long de la molécule. La thymine et la cytosine sont des pyrimidines, c’est-à-dire des bases constituées d’un seul cycle hexagonal d’atomes d’azote et de carbone. L’adénine et la guanine sont des purines, faites de deux cycles, l’un hexagonal et l’autre adjacent de forme pentagonale, contenant tous deux de l’azote et du carbone. Remarquons que les deux classes fondamentales de bases, les purines et les pyrimidines, représentent des molécules de dimensions différentes, à cause de la présence d’un ou de deux cycles. Les purines occupent donc plus d’espace que les pyrimidines, observation qui constitua l’une des clefs de la découverte de la structure de l’ADN par James Watson et Francis Crick en 1953.
DOUBLE HÉLICE ET DIFFÉRENTES FORMES DE L’ADN
Une molécule d’ADN à l’état naturel, c’est-à-dire à l’intérieur d’une cellule vivante, est formée de deux chaînes polynucléotidiques (chaînes formées de nucléotides dans lesquels se répètent phosphate-désoxyribose-base), appariées et enroulées en une spirale, pour former une double hélice .
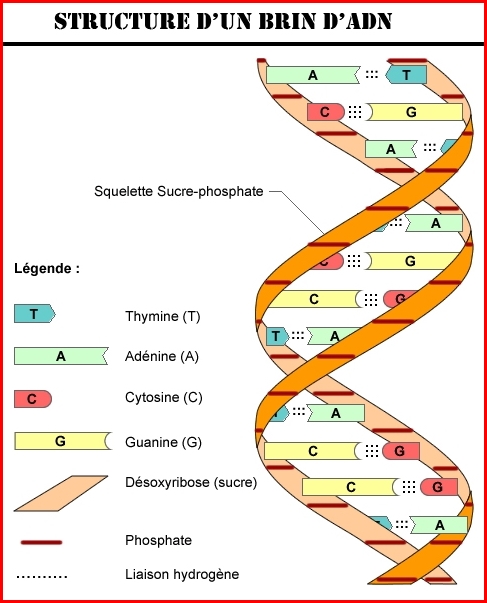
BASES COMPLÉMENTAIRES
L’appariement des deux chaînes polynucléotidiques de l’ADN se fait de façon très simple, grâce à la complémentarité des bases. Parmi les bases puriques, l’adénine présente deux régions, un atome d’azote et un groupe -NH (azote-hydrogène), qui peuvent former des liaisons hydrogène, avec des groupes semblables appartenant à d’autres bases (liaisons chimiques). Des trois autres bases, seule la thymine (une pyrimidine) est capable de former deux liaisons hydrogène, l’une au moyen d’un groupe -NH, et l’autre grâce à un atome d’oxygène. L’autre purine, la guanine, est capable par contre de former trois liaisons hydrogène, grâce à deux groupes -NH et à un atome d’oxygène. Trois liaisons du même type peuvent être formées également par l’autre pyrimidine, la cytosine, dans ce cas également à travers deux groupes -NH et un atome d’oxygène. Ces propriétés chimiques permettent un appariement extrêmement spécifique de deux chaînes contiguës d’ADN.
LA STRUCTURE TRIDIMENSIONNELLE
La structure tridimensionnelle de la double hélice d’ADN (voir paragraphe précédent) est formée de deux spirales enroulées l’une autour de l’autre, avec les bases accouplées vers l’intérieur de la molécule (l’adénine avec la thymine, et la cytosine avec la guanine). À l’extérieur des bases, se trouvent les sucres, et à l’extérieur de ces derniers, les groupes phosphate, avec la charge électrique négative, responsable de la légère acidité de la molécule. Vue de profil, la double hélice présente deux sillons en spirale, le gros sillon et le petit sillon. La molécule est dextrogyre (c’est-à-dire que la spirale tourne vers la droite). La forme d’ADN que nous venons de décrire s’appelle forme B, c’est celle qui fut découverte par James Watson et Francis Crick et qui se trouve normalement à l'intérieur de la cellule.
RÉPLICATION
Dans l'article où ils annonçaient la découverte de la structure de l'ADN, James Watson et Francis Crick insérèrent une phrase qui est passée dans l'histoire de la science comme l'une des plus courtes mais les plus riches de sens jamais publiées. Les deux biologistes écrivirent que « les implications que la structure de l'ADN a pour la réplication de l'information génétique » ne leur avaient pas échappé. En d’autres termes, ils s'étaient bien rendu compte que, une fois la structure de l'ADN déchiffrée, le mystère de la réplication (ou de la duplication) de l'ADN serait bientôt élucidé. En fait, les deux chercheurs travaillaient déjà à un deuxième manuscrit dans lequel ils décrivaient ce mécanisme.
Réplication semi-conservative de l'ADN
Chacune des deux chaînes polynucléotidiques, qui s’enroulent l’une autour de l’autre formant une double hélice, sont composées d'éléments complémentaires deux à deux : une base thymine (T) se lie à une base adénine (A), une base cytosine (C) à une base guanine (G), et inversement. Pendant le processus de réplication, qui consiste en la formation de copies de la molécule d’ADN, la double hélice s'ouvre, les deux chaînes se séparant et servant chacune de matrice pour la création d’une nouvelle chaîne selon les règles de la complémentarité. Le résultat final est la formation de deux doubles hélices, chacune contenant l'un des deux brins originaux (brin « parental ») et un nouveau brin (brin « néosynthétisé »). Cette réplication est dit semi-conservative (parce qu'elle conserve l'un des deux brins originaux dans chaque nouvelle copie d'ADN). Elle fut décrite sur des bases exclusivement théoriques comme le mode de réplication le plus adapté étant donné la structure de l’ADN.
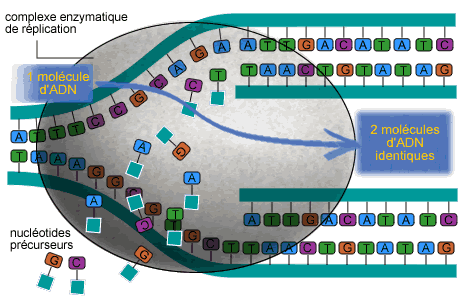
EXPÉRIENCES SUR LA RÉPLICATION
La nature semi-conservative du processus de réplication de l’ADN fut proposée par James Watson et Francis Crick sur des bases purement théoriques. Matthew Meselson et Franklin Stahl en firent la première démonstration pratique vers la fin des années 50, en utilisant la Bactérie intestinale Escherichia coli. Meselson et Stahl disposaient d’une ultracentrifugeuse capable de séparer des ADN selon leur densité. Et la densité de l’ADN peut être modifiée par l’introduction dans la molécule de différents isotopes de l’azote : l'isotope 15 (15N) est dit « lourd » par rapport à l'isotope ordinaire 14 (14N). Les scientifiques ont donc mis en culture les Bactéries, d’abord sur un milieu ne fournissant que de l’azote lourd, marquant ainsi l’ADN, puis sur un milieu à azote léger. Après une première génération de Bactéries, Meselson et Stahl isolèrent une partie de leur ADN et le centrifugèrent. Ils obtinrent alors de l’ADN présentant une densité inférieure à celle de l’ADN parental. La deuxième génération produisit deux densités différentes, l’une identique à celle de la génération précédente, et l’autre encore plus faible. Ces résultats étaient conformes aux prévisions de la théorie semi-conservative. En partant de molécules à deux hélices lourdes, une réplication aurait dû produire des molécules hybrides, avec un brin lourd (le brin parental) et un léger (le brin synthétisé). Un cycle de réplication supplémentaire aurait produit des molécules hybrides (lourde-légère) et des molécules entièrement constituées de chaînes légères, exactement comme l’avaient démontré les deux biologistes.
Une démonstration de la réplication semi-conservative très semblable fut menée par Herbert Taylor en 1958, en utilisant des chromosomes de fève. Taylor provoqua un cycle de réplication cellulaire en présence de thymidine tritiée (c’est-à-dire marquée radioactivement). Celle-ci fut incorporée dans les chromosomes de fève, dont les quatre bras devenus radioactifs étaient bien visibles au moment de la métaphase mitotique (la division cellulaire peut être arrêtée à ce stade par une substance chimique spéciale, la colchicine). Pendant la deuxième division, les chromosomes à quatre bras ne présentaient cependant que deux bras marqués radioactivement, tandis que les deux autres étaient normaux. Comme la réplication avait eu lieu dans un terrain de culture où la thymidine tritiée était absente, ces résultats étaient en parfait accord avec la théorie de la réplication semi-conservative.
MUTATIONS
Les mutations constituent un phénomène essentiel dans le domaine génétique. Elles permettent aux populations d’organismes vivants d’augmenter leur variabilité, pour que la sélection naturelle puisse agir efficacement et déboucher sur le processus que nous appelons évolution biologique. En résumé, une mutation est un événement ayant pour effet de modifier de façon permanente la structure du matériel héréditaire : l’ADN. Les biologistes distinguent trois types de mutations : géniques, génomiques, et chromosomiques.
MUTATIONS GÉNIQUES
Les mutations géniques sont les plus communes. Elles sont de trois sortes : substitution d’une base par une autre, délétion d’une base dans la séquence d’ADN, ou addition d’une nouvelle base en un point quelconque de la séquence (voir La composition chimique de l’ADN). Bien qu’il y ait quatre types de bases dans l’ADN (adénine, cytosine, guanine et thymine), elles sont chimiquement semblables deux à deux. L’adénine et la thymine sont des purines, tandis que la cytosine et la guanine sont des pyrimidines. Une base donnée peut être transformée par mutation en n'importe laquelle des trois autres, mais les mutations qui transforment une purine en une autre purine, ou une pyrimidine en une autre pyrimidine sont beaucoup plus fréquentes que celles qui transforment une purine en une pyrimidine (ou inversement). Cela tient au fait que le changement d’une substance en une autre, de structure chimique semblable, est moins compliqué, et donc plus probable que le changement en une substance dont la structure est moins ressemblante. Parfois, une base peut être éliminée par une séquence, ou une nouvelle base peut être ajoutée. Dans ce cas, la séquence du gène correspondant sera lue de façon très différente par l’ARN-polymérase, parce que tous les triplets qui constituent les mots de l’alphabet génétique seront altérés en aval de la mutation (voir code génétique).
MUTATIONS CHROMOSOMIQUES
Une catégorie plus rare de mutations est constituée de ce qu’on appelle les mutations chromosomiques. Des morceaux entiers de chromosomes sont éliminés, ou vont se fondre avec d’autres chromosomes déjà existants. Dans un cas comme dans l'autre, des dizaines, voire des centaines de gènes se retrouvent déplacés. Étant donné que la régulation de l’activité d’un gène dépend en partie de sa localisation dans le génome, les mutations chromosomiques ont en général des effets extrêmement dramatiques, car elles altèrent la quantité de produit génique, ou modifient le moment où un gène donné est activé ou désactivé.
MUTATIONS GÉNOMIQUES
Les mutations génomiques ont lieu lorsqu’une configuration chromosomique entière est répliquée, ou bien lorsque les chromosomes de deux génomes différents se fondent dans la même cellule. Dans la nature, ces phénomènes, qui se produisent rarement, sont résumés sous le terme « polyploïdie ». Un individu polyploïde peut naître de la fusion des gamètes de deux espèces différentes, ou de la non-réduction du nombre chromosomique pendant la méiose. Les mutations génomiques sont en général désastreuses pour un organisme, car elles bouleversent le fragile équilibre des fonctions de milliers de gènes. Malgré cela, il est fréquent que de nouvelles espèces de plantes voient le jour par polyploïdie, alors que le phénomène est bien plus rare chez les animaux.
AGENTS MUTAGÈNES
Qu’est-ce qui provoque les mutations ? Plusieurs agents physiques et chimiques sont en mesure de produire les trois types de mutations : géniques, génomiques et chromosomiques (voir précédents paragraphes). Les hautes températures, les radiations de toute nature (des rayons ultraviolets aux rayons gamma), ainsi que différentes substances cancérigènes (y compris la saccharine, la nicotine et la caféine), sont autant de facteurs de mutations tant chez les plantes que chez les animaux, y compris l’homme. Une mutation est simplement une modification chimique ou physique de la structure de l’ADN. Ses effets délétères (ou, plus rarement, bénéfiques) sont dus à un changement dans le type ou dans la séquence des bases. L'information contenue dans l’ADN est alors modifiée, produisant des protéines aux fonctions nouvelles. Ces dernières peuvent à leur tour changer le phénotype de l’organisme concerné, qualifié alors de « mutant » .
RÉPARATION DE L’ADN ENDOMMAGÉ
L’ADN peut être endommagé par des agents mutagènes, c’est-à-dire par des agents physiques qui provoquent des mutations. En outre, au moment de la réplication, l’ADN-polymérase peut insérer une base en mauvaise position. Ces deux problèmes peuvent être corrigés par une série d'enzymes qui remplissent des fonctions spéciales, et qui sont dites « réparatrices » .
Supposons qu'une erreur de réplication ou une mutation ait provoqué la formation d’un dimère de thymine (c’est-à-dire d’un appariement latéral de deux thymines, qui se sont liées entre elles et non pas avec leurs adénines respectives sur l'hélice complémentaire). L'erreur est découverte par l’ADN-polymérase, qui remplit la fonction de « correction d’épreuves » (l'enzyme compare la séquence du nouveau brin avec celle de l'ancien, pour localiser d'éventuelles erreurs). L'enzyme nucléase coupe alors le brin endommagé en deux points autour de la zone où l'erreur s'est produite. Cela crée une zone vide, où seulement l'une des deux hélices est présente. L’ADN-polymérase utilise la portion découverte de l'hélice intacte comme modèle de réplication pour remplacer la coupure provoquée par la nucléase. Enfin, l'ADN-ligase intervient pour recoller les morceaux, refermant le brin endommagé, cette fois avec la séquence de bases voulue.
L’ADN ET LE MATÉRIEL GÉNÉTIQUE
Aujourd’hui les biologistes donnent pour acquis le fait que l’ADN est la molécule qui sert de support à l'information génétique, mais la situation était bien différente dans la première moitié du XXe siècle. Sur la base d’analyses purement chimiques, on savait que l’ADN était constitué de quatre types de substances (ce qu'aujourd’hui nous appelons nucléotides). Par ailleurs, on savait que les protéines étaient constituées de vingt types différents de « briques » fondamentales (les aminoacides). En toute logique, il semblait que les protéines, disposant d’un alphabet de 20 lettres, avaient la capacité de stocker beaucoup plus d'informations que l’ADN avec son alphabet de 4 lettres (c'est là l'un des nombreux exemples où la nature ne suit pas la logique humaine).
En 1928, l’Anglais Frederick Griffith, qui étudiait le virus responsable de la pneumonie, remarqua qu'en mélangeant une souche virulente et une souche non virulente, cette dernière devenait capable de provoquer la maladie. Cette transformation avait lieu même si la souche non virulente était mélangée avec une souche virulente rendue inactive ! Il était donc clair qu'une substance chimique était passée des virus morts aux virus vivants, et les avait transformés. Plusieurs biologistes tentèrent d’isoler la substance en question. En 1944, les Américains Oswald Avery, Maclyn McCarty et Colin MacLeod annoncèrent qu’il s’agissait d’ADN, et non de protéines comme on l'avait pensé jusqu’alors. Mais le monde scientifique n'était pas encore prêt à apprécier l'importance de l’ADN : cette découverte fut accueillie avec un grand scepticisme.
Ce n'est qu'en 1952 (un an avant la découverte de la structure de l’ADN par James Watson et Francis Crick) qu'Alfred Hershey et Martha Chase publièrent la première démonstration irréfutable que l’ADN est le support de l'information génétique. Hershey et Chase profitèrent de la possibilité de marquer radioactivement (voir aussi génome des Procaryotes) les protéines et l’ADN, en utilisant deux éléments radioactifs différents.
De nombreuses protéines peuvent être marquées avec l’isotope 35 du soufre, l’un de leurs constituants. L'ADN, quant à lui, peut être marqué avec l’isotope 32 du phosphore, qui est l’un de ces éléments structurels.
Les deux chercheurs marquèrent les protéines et l’ADN de bactériophages, ou phages (virus parasites de Bactéries), mis en culture et les mélangèrent à une culture bactérienne. Les deux populations mêlées furent soumise à la centrifugation, ce qui sépara les Bactéries (plus lourdes) des lers bactériophages (plus légers). L’objectif était simplement de vérifier s'il y avait de l'ADN ou des protéines marquées à l’intérieur des Bactéries. L'une des deux molécules devait avoir été introduite par les phages dans leur tentative de parasiter les Bactéries. Hershey et Chase découvrirent que c'était l’ADN, et non pas la partie protéique, qui avait envahi les Bactéries. Ce n'est pas tout. Si on laissait l’ADN dans les Bactéries, celles-ci présentaient les marques d’une attaque de bactériophages et produisaient une nouvelle génération de leurs propres parasites !
GÈNES ET PROTÉINES
Une molécule d’ADN est extrêmement longue. Chez une Bactérie, type de cellule parmi les plus simples, la molécule d’ADN complètement déroulée et despiralisée mesure plusieurs millimètres, soit environ mille fois plus que la cellule elle-même. Un gène se présente physiquement comme un court segment de la molécule d’ADN contenant l'information nécessaire à la synthèse d’une protéine spécifique. À chaque gène correspond en général une protéine. V. Ingram fut parmi les premiers à étudier cette correspondance entre gènes et protéines, établissant ainsi les fondements de la biologie moléculaire. En 1957, Ingram démontra qu'une modification dans la séquence nucléotidique d’un gène (c’est-à-dire une mutation) correspond à un changement dans la séquence d’aminoacides qui compose une protéine. Cette démonstration fut faite à partir de l'étude sur l'anémie falciforme, maladie héréditaire de l’homme causée par la production d’une hémoglobine (protéine responsable du transport de l’oxygène et du gaz carbonique dans le sang) défectueuse. L’hémoglobine à l’origine de l’anémie est presque identique à l'hémoglobine normale : seul l'un de ses 287 aminoacides est défectueux. Cette altération correspond à une mutation spécifique dans la séquence du gène qui code l’hémoglobine. Dans les années qui suivirent, C. Yanofsky démontra de façon plus générale que chaque mutation induite dans le gène qui code l'enzyme triptophane synthétase dans la Bactérie Escherichia coli provoque un défaut différent dans la protéine, dû précisément au remplacement d’un aminoacide par un autre.
GÈNES ET NON PROTÉINES
On dit qu'à un gène correspond un produit protéique. En d’autres termes, le gène est transcrit en ARN messager pour être ensuite traduit par l'appareil de la synthèse protéique afin de générer une protéine (voir transcription et la traduction). Il existe cependant deux autres classes de gènes qui codent deux types distincts d’ARN : l'ARN de transfert et l'ARN ribosomal. Ces gènes, transcrits par des enzymes particulières, expriment comme produit final des molécules d’ARN qui ne sont pas traduites en protéines, mais qui sont cependant intimement liées à la synthèse protéique. En effet, l'ARN ribosomal constituera le ribosome, tandis que les ARN de transfert se lieront à leurs aminoacides respectifs, qui seront ensuite assemblés pour donner une protéine.
LE CODE GÉNÉTIQUE
L'ADN contient l'information génétique nécessaire à la production des protéines, à travers les processus de transcription et de traduction, qui font appel aux différents types d’ARN. Cette information consiste en une séquence particulière des quatre bases : adénine, cytosine, guanine, et thymine (voir composition chimique de l’ADN). Mais quel est l’ordre d’agencement des bases de la séquence qui permettra de spécifier la structure d’une protéine ? C’est le code génétique qui permet d’établir des correspondances entre les gènes et les protéines. Ce code est un véritable « dictionnaire » cellulaire, qui permet aux ribosomes de traduire la séquence de bases dans la séquence d’aminoacides voulue.
On peut se représenter la séquence des bases de l’ADN comme la séquence des lettres d’un texte. La séquence prise en elle-même n'a aucun sens, si la personne qui lit ces lignes ne connaît pas le code particulier de la langue française. La même séquence de symboles serait incompréhensible pour un lecteur chinois ou américain (à moins qu'il n'ait appris le code). Les bases de l’ADN, qui en elles-mêmes ne fournissent pas d'information, doivent donc être combinées d'une façon ou d'une autre pour former des « mots » et des « phrases » que les ribosomes puissent comprendre. Mais les mots du dictionnaire génétique, sont-ils tous de même longueur ? Quelle est leur longueur ? Existe-t-il des signes de ponctuation qui marquent la fin d’un mot ou d’une phrase ? La réponse à ces questions, qui constitue l'un des chapitres les plus fascinants de l’histoire de la biologie moléculaire, commença par la démonstration que les mots ont tous la même longueur et qu’ils sont faits de trois éléments.
LES TRIPLETS
Le premier pas sur la voie de l'interprétation du code génétique consista à comprendre que la séquence qui spécifie chaque aminoacide dans une protéine doit être constituée d'au moins trois lettres. Cette conclusion dérive d'une simple observation. Il existe quatre types de bases (« lettres ») et vingt types d’aminoacides (« mots »). Si le code génétique était fondé sur des mots d’une seule lettre, chaque séquence d’ADN pourrait spécifier au maximum 4 types d’aminoacides. Si chaque aminoacide était codé par deux bases, il y aurait 16 combinaisons possibles, et donc un nombre encore insuffisant (d'autant plus que le message doit contenir des signes de ponctuation et des espaces pour indiquer le début et la fin d’un gène et pour séparer les différents gènes, faute de quoi le génome entier serait transcrit et traduit comme un simple « supergène »).
UN CODE DÉGÉNÉRÉ
Une fois établi que le code génétique se fonde sur des triplets, comment peut-on reconstruire le dictionnaire complet, autrement dit comment peut-on savoir à quel aminoacide chaque triplet de bases correspond ? De plus, étant donné qu'il n'existe que 20 aminoacides et 64 combinaisons des quatre bases prises trois par trois, quel est le sens des 44 combinaisons restantes ? Des chercheurs ont élaboré une méthode simple pour répondre à ces problèmes : construire des ARNm artificiels dont la séquence est connue, les mettre en présence des ribosomes et des enzymes nécessaires, puis récupérer les protéines produites pour analyser leur séquence d’aminoacides. C'est ainsi qu'on a découvert, par exemple, que le triplet CUC (cytosine-uracile-cytosine) est reconnu par le ribosome comme correspondant à la leucine, et que cet aminoacide est ajouté à la protéine en cours de formation. Le triplet GUC correspond à l'aminoacide valine, l'UAU au tryptophane, et ainsi de suite. Plusieurs triplets, cependant, codent pour le même aminoacide. Par exemple, UGU et UGC spécifient tous deux la cystéine. Aussi le code génétique est-il dit « dégénéré » : un aminoacide peut être codé par plus d’un triplet. Enfin, certains triplets ne codent aucun aminoacide. Il s'agit des triplets UAA, UAG et UGA. Ces triplets, dits stops, ou codons de terminaison, signalent la fin d’un gène, et par conséquent interrompent le processus de synthèse protéique à l’intérieur du ribosome.
L'ARN
L'acronyme ARN est l’abréviation d'acide ribonucléique. Chimiquement, l'ARN - comme l’ADN - est un acide faible constitué d'une séquence de nucléotides contenant chacune une base azotée, un sucre et un groupe phosphate chargé négativement (voir composition chimique de l’ADN). Le sucre qui entre dans la composition de l’ARN est le ribose, tandis que, dans le cas de l’ADN, on a à sa place le desoxyribose - c’est-à-dire un ribose auquel il manque un groupe hydroxyle. L'ARN, tout comme l’ADN, comporte quatre types de bases. Trois d'entre elles - l'adénine, la cytosine, et la guanine - sont les mêmes que l’ADN. La quatrième base est l'uracile, au lieu de la thymine propre à l’ADN. Une autre différence fondamentale entre l’ADN et l'ARN est que, tandis que le premier se trouve dans la nature en général sous la forme d’une double hélice, le deuxième n'est présent à l’intérieur des cellules vivantes que comme hélice simple. Cette différence est étroitement liée aux fonctions que ces deux molécules remplissent dans le contexte du métabolisme cellulaire : conservation et duplication de l'information génétique dans le cas de l’ADN ; traduction et diffusion de l'information dans le cas de l’ARN. Il existe trois types fondamentaux d’ARN : messager, de transfert et ribosomal.
L'ARN MESSAGER (ARNm)
L'ARN messager est la molécule formée par l'ARN-polymérase, enzyme ayant pour fonction de reconnaitre la séquence de bases de l’ADN. L'ARN messager (ou ARNm) des Procaryotes est en général polycistronique, c'est-à-dire qu'il porte l'information nécessaire pour coder plus d’un gène, ou cistron (voir aussi opéron). Inversement, l'ARN messager des Eucaryotes produit à l’intérieur du noyau cellulaire, est monocistronique, c’est-à-dire qu'il code pour un seul gène. En outre, chez les Eucaryotes, quand la polymérase finit de « lire » le brin d’ADN, le produit de la transcription est libéré. Un groupe d’enzymes découpe alors certaines parties ne contenant pas l'information nécessaire à la production d’une protéine (ces parties sont des séquences correspondant aux « introns » dans l’ADN). D'autres enzymes se chargent d’attacher un « capuchon » ou chapeau (cap en anglais) et une « queue » à l'ARNm. Ces modifications permettent à la molécule d’être reconnue par une autre catégorie de protéines, qui la transportent à l'extérieur du noyau, dans le cytoplasme. Une fois dans le cytoplasme, l'ARNm est reconnu par une catégorie de particules ribonucléoprotéiques spéciale, les ribosomes. À l’intérieur des ribosomes, le message porté par l'ARNm est lu de nouveau et la protéine correspondante - spécifiée par la séquence d’ADN - est générée (voir transcription et la traduction).
L'ARN DE TRANSFERT (ARNt)
Le deuxième type d’ARN est l'ARN de transfert, ou ARNt. Par rapport à l'ARNm, l'ARNt est une molécule de dimensions très réduites et a une fonction bien différente, quoique complémentaire de celle du premier. Il existe environ une vingtaine de groupes d’ARNt, dits isoaccepteurs, un pour chacun des 20 aminoacides dont sont constituées les protéines. Chaque ARNt est caractérisé par une structure en forme de trèfle à quatre feuilles, présentant quatre « bras ». L'un d'entre eux, dit bras de l'anticodon, présente une séquence de trois bases complémentaire du triplet de l'ARNm qui porte le message pour un aminoacide donné. Un autre bras, dit accepteur, porte l'aminoacide particulier que cet ARNt donné est chargé de livrer au ribosome (le siège où les différents aminoacides transportés par les molécules d’ARNt sont assemblés pour former la protéine finale). La complémentarité de l'ARNt avec l'ARNm consiste en ceci : puisque, par exemple, le triplet de bases UCA (uracile - cytosine - adénine) de l'ARNm code pour l'aminoacide sérine, l'ARNt qui transporte la sérine au ribosome est caractérisé par le triplet complémentaire, AGU (adénine-guanine-uracile), dit anticodon. Le triplet de l'ARNt s'aligne sur celui de l'ARNm à l’intérieur du ribosome, suivant un processus qui constitue l'un des passages fondamentaux de la synthèse des protéines.
L'ARN RIBOSOMAL (ARNr)
Le dernier type d’ARN est l'ARN ribosomal, indiqué en général par un nombre suivi de la lettre S, par exemple 16S, ou 5S. Le nombre indique les dimensions de la molécule, tandis que le S ( pour Svedberg) correspond au coefficient de sédimentation (mesure relative aux dimensions). Par exemple, l'ARN 16S a un poids moléculaire de 550 000 et mesure approximativement 1 600 nucléotides de longueur ; l'ARN 5S, en revanche, a un poids moléculaire de 36 000, et mesure environ 120 nucléotides de longueur (remarquons que les purines pèsent plus que les pyrimidines, car la structure moléculaire du premier type de bases est plus complexe que celle du deuxième type. Par conséquent, deux ARN peuvent contenir exactement le même nombre de bases, mais avoir des poids moléculaires très différents). L'ARN ribosomal est en général abrégé en ARNr. Ce nom, comme il est facile de le comprendre, dérive du fait que l’ARNr se trouve à l’intérieur des ribosomes. Les ribosomes sont par conséquent des particules ribonucléoprotéiques, constituées en partie de protéines et en partie d'ARNr. Contrairement à l'ARNm et à l'ARNt, l’ARNr n'est pas directement impliqué dans la spécification du type d’aminoacide ou de protéine qui doit être produit. Sa fonction est plus de nature structurelle, en ce sens qu'il fait partie de l'« épine dorsale » du ribosome
LA TRANSCRIPTION ET LA TRADUCTION
Nous savons aujourd'hui que les gènes et les protéines sont liés par deux phénomènes fondamentaux qui régissent la vie de chaque cellule et, par voie de conséquence, tout organisme végétal ou animal : la transcription et la traduction. La transcription est le processus en vertu duquel des segments de la double hélice de l’ADN sont lus par un complexe enzymatique spécial, l'ARN-polymérase. Ce complexe crée, base après base, un brin d’ARN messager caractérisé par une séquence de bases parfaitement complémentaire de celle de l’ADN de départ. De cette façon, l'information contenue dans un gène déterminé est littéralement transcrite sous forme de modèle, de façon très semblable à ce qui a lieu dans le processus de réplication (ou duplication) de l’ADN. La seule différence est que le produit final est un acide ribonucléique à une seule hélice et non une nouvelle double hélice d’ADN.
Une fois que l'ARN messager a été synthétisé, dans le cas des Eucaryotes, il passe du noyau au cytoplasme, dans lequel le message peut être traduit en protéine. La traduction a lieu à l’intérieur de structures subcellulaires spéciales, les ribosomes. Le processus, qui prend le nom de synthèse protéique, consiste à lier les aminoacides les uns aux autres, composant la protéine. Les ribosomes sont des particules constituées de protéines et d'un type spécial d’ARN, l'ARN ribosomal. À l’intérieur de chaque ribosome, le brin d’ARN messager est apparié avec un autre type d’ARN, l'ARN de transfert (ou ARNt), qui transporte un aminoacide à la fois et le positionne pour qu'il puisse être ajouté à la chaîne protéique en voie de synthèse. Aminoacide par aminoacide, le ribosome assemble ensuite la protéine tout entière, comparant l'information contenue dans l'ARN messager avec l'ARN de transfert approprié. La protéine, une fois libérée par le ribosome, est dans de nombreux cas prête à remplir sa fonction dans le contexte du métabolisme cellulaire, tandis que dans d'autres cas elle doit subir une élaboration à l’intérieur d'organites cellulaires particuliers.